
Encoding Excellence
Strategic Use of Embedding for Source Code


As artificial intelligence (AI) and machine learning (ML) continue to evolve, practitioners are facing the daunting task of optimizing every step of the problem-solving process. With the influx of tools like Large Language Models (LLMs) and automated systems, the temptation to adopt a 'plug-and-chug' approach is high. Initially, ‘plug-and-chug’ may give a working solution, but over time this solution lacks adaptability to improve as generic solutions may not account for problems specific to the business contexts. How do we balance the quickness to finding a solution with the need for customized, reliable and accurate solutions?
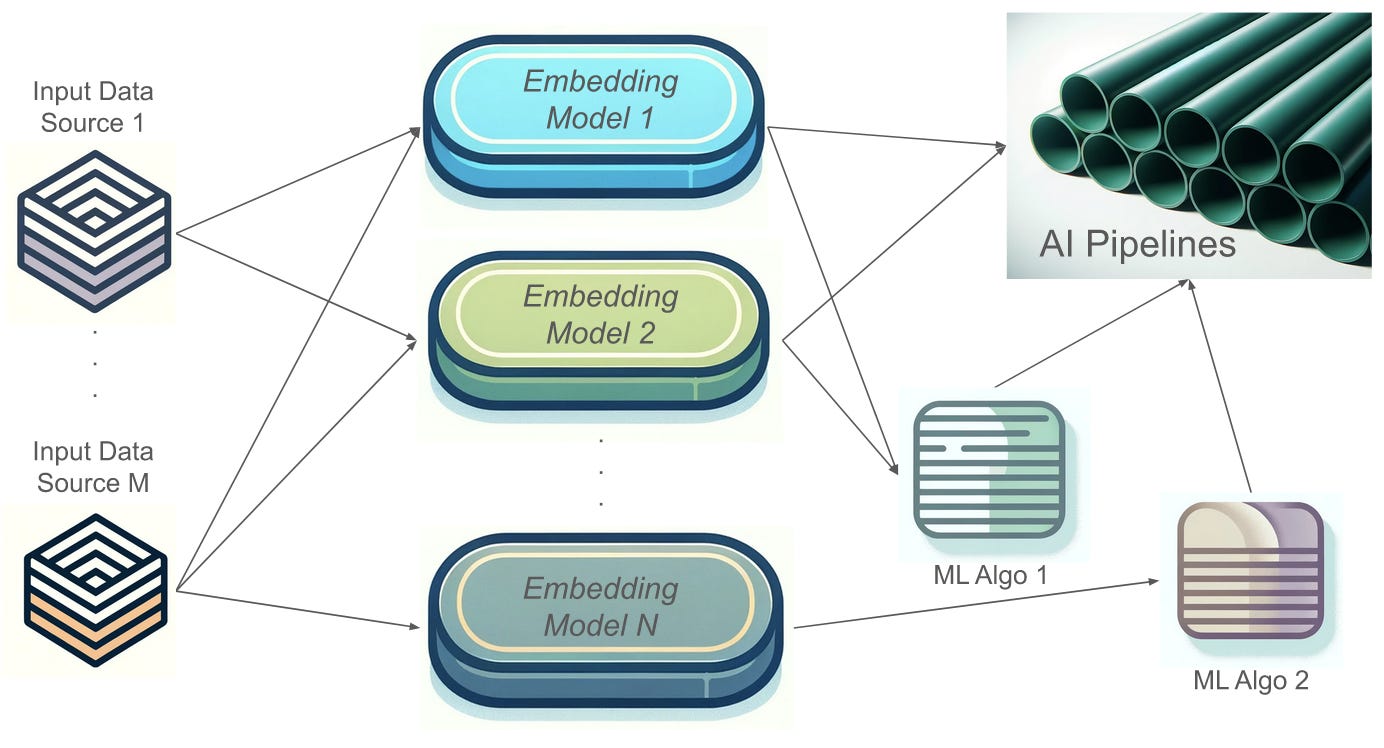
In this blog, we cover the challenges in optimizing AI technology pipelines and how Encoder can streamline one of the most critical phases—the embedding process. This step is pivotal in selecting the right approaches to solve specific, customized problems. In addition, writing blocks of code to test multiple embedding strategies for every business use case is hard to scale, even for a highly efficient AI/ML team; so having a dedicated software to manage this step is crucial for AI customization success.
Being able to run embedding strategies efficiently, we also start to see how there are interesting features to unveil in the embedded data–if we do not intentionally explore different embedding models and visualize their results, we can never be sure we have understood the data and that the information we are extracting is usable for downstream automation.
In a fast-paced environment, especially with the excitement of AI adoption everywhere, practitioners often find it challenging to thoroughly investigate embedding models. This step, while being one of the initial phases in the sequence of developing an AI product, often receives less visibility yet is crucial for setting the stage for success. Encoder is designed to support practitioners in mitigating these challenges and be a versatile tool in their quest to build better AI products.
Challenges of Input Data for AI/ML Pipelines
In many AI/ML projects, we need to process and/or combine a variety of datasets to make the best use of available information. In fact, data processing is a major, time-consuming step in practice. Sometimes, it’s even referred to as a step that’s more art than science.
In this crucial yet intricate step, the practitioner is actively dealing with many challenges including the following: extracting the most appropriate features from the data, handling the size of the data (dimension analysis and reduction), thinking through potential bias and fairness, and dealing with the dynamics of the data through time, etc. In source code embedding, for example, the practitioner is challenged to extract multi-language features (Java, Golang, Python, etc) and learn how these features relate to each other. There’s really no one-size-fits-all embedding model in solving these challenges, so the approach we take should aim to find the most appropriate model(s) to solve these challenges for every problem.
A fundamental technique in data processing that practitioners employ is embedding. It is an encoding process that maps the data into a new format and space that enhances its utility while preserving valuable information. For example, we can map code files (code blocks and comments) into a space represented by numbers. Embedding not only simplifies the handling of complex data but also prepares it for more efficient and effective downstream analysis and processing. Selecting the most appropriate embedding model will make solving the problem at hand much easier.
Advantages of Encoding with Encoder
While embedding can be immensely beneficial in AI applications, it remains a predominantly manual and intricate process. In reality, there are way too many models to choose from. You may have a favorite model for your AI/ML field, you may find one of the “best” models ranked on the Hugging Face MTEB leaderboard, use one of the models made available by OpenAI, or you may fine-tune a pre-trained model on your own. Performing one or two embedding strategies on a single data input might be straightforward, but the challenges multiply when various data sources are integrated, such as in building a Retrieval-Augmented Generation (RAG) system, a technique reviewed by Gao et al, 2024. The selection of an embedding process grows increasingly complex given the varied context of the problem, the volume of data, and the diversity of data types involved.
Even when there’s a good reason to choose one of the embedding models over others, the right steps to take are to 1) produce and 2) compare embedding results using these models in the decision-making process. Simply adopting an embedding model because it is recommended by others, without a deep understanding of its fit for the specific project needs, can jeopardize critical decisions in a high-stakes AI project.
Encoder is designed to make the selection process much easier. In Encoder, we can launch multiple embedding models quickly. In Figure 2, we have a screenshot of deployed embedding models.
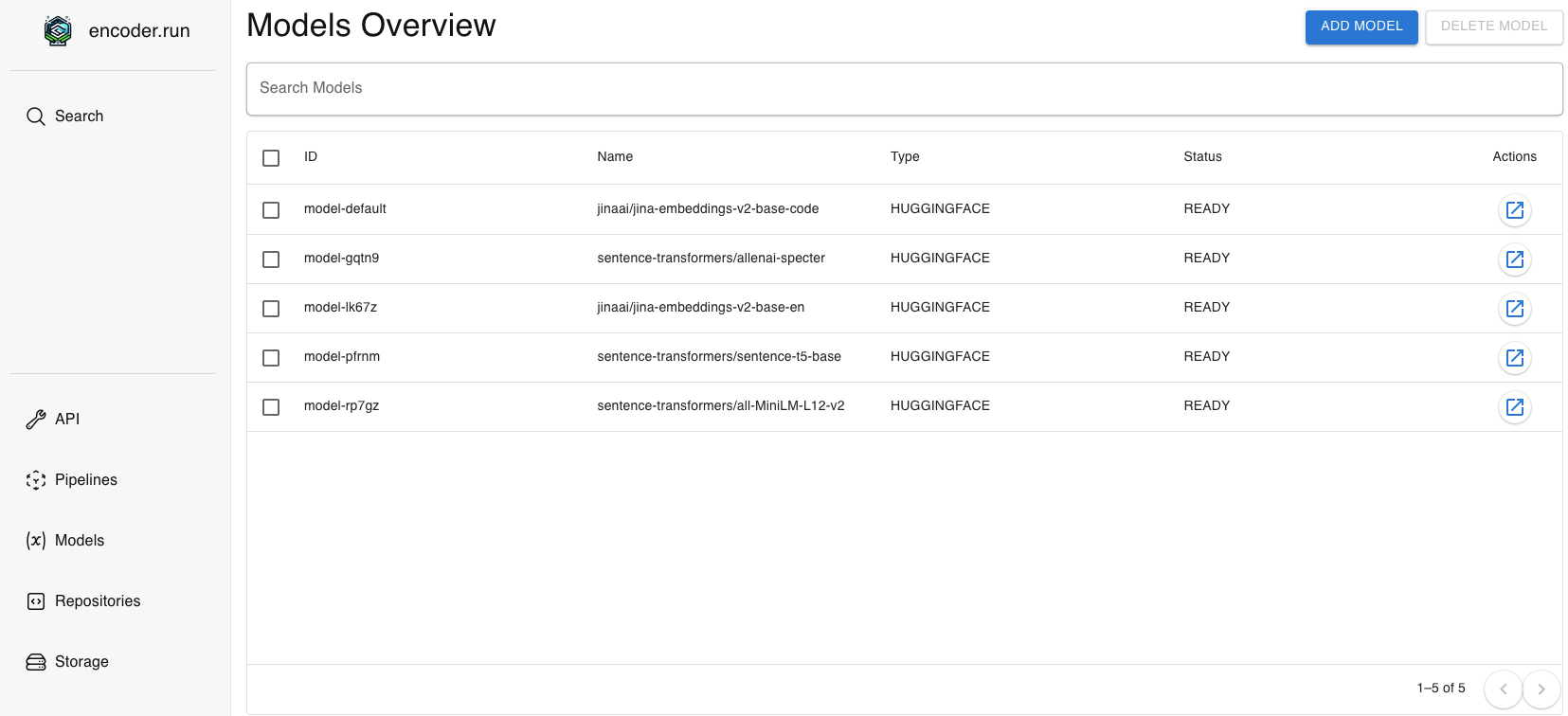
We can then use these models to launch embedding pipelines on various repositories. The embedded data are saved in a storage instance(s) that’s also managed by the Encoder application.
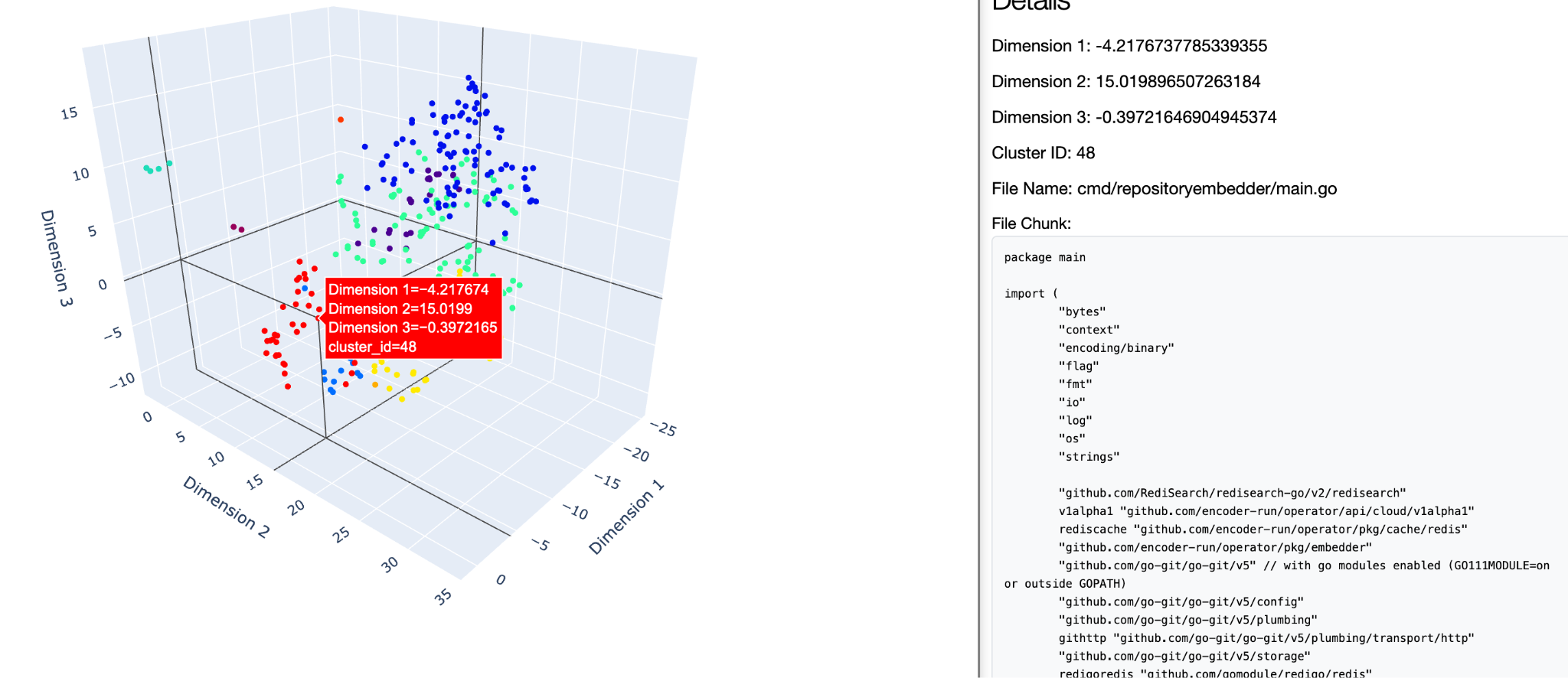
After a pipeline run is complete, we can obtain the embedded data from the storage instance to take a look. In Figure 3, we have a plot showing a portion of the embedding result of the Encoder code repository (it’s open source!). This plot is constructed with outputs from a 3D t-SNE embedding over the original 768-dimensional data space using the jina-embeddings-v2-base-code model; clustering is applied for ease of visualization. We can simultaneously visualize the original content of the file chunk (right panel) while browsing through the embedded data points (left panel). This scanning process can help us quickly understand if similar file chunks are next to each other in the embedded space. In addition, we can also explore how different each type of files are and if we need to apply different embedding models to different file types. Figure 4 shows how we can visually inspect the distribution of the file clusters, which can be helpful in further understanding as well as implementing advanced processing techniques such as anomaly detection and filtering.
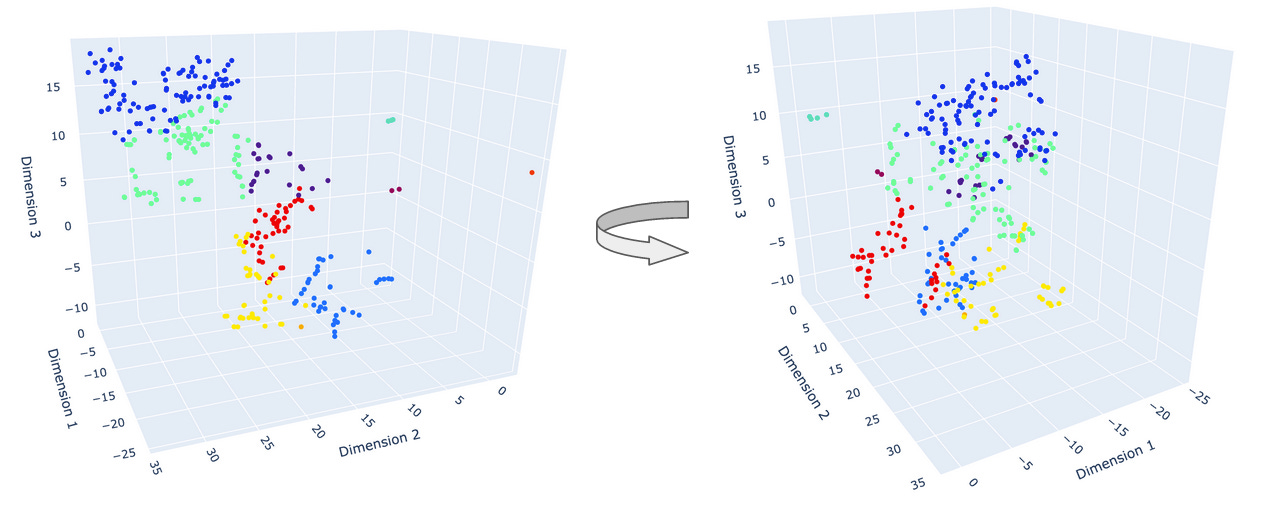
With Encoder, we find it easy to launch multiple embedding models and collect the necessary data. Downstream, we explore the embedding results to visually inspect similarities and differences between the input data points. Previously, this process was harder to launch and the results too messy to organize (practitioners usually leverage Jupyter notebooks, which can quickly become unwieldy in keeping track of all the models and embedding data produced, not to mention sharing this information within and across stakeholder teams).
Run Encoder
This blog explores how Encoder, a specialized tool to effectively explore different encoding and embedding models, can ensure the use of the most effective algorithms and models. We focus on source code embedding, which is the foundation of effective algorithms and systems for source code semantic search and retrieval-augmented generation across modern multi-language repositories.
If you are curious about how embedding optimization can help your AI/ML projects, try Encoder.
If you found this helpful, please share and consider joining the Encoder community to help make AI/ML automation easier. We would love to hear from you!
About
This is a technical blog in an ongoing series [encoder.run on substack] that captures features and use cases of Encoder, an open source application to deploy various models and create pipelines to produce embedding data in an efficient and scalable way.